12 Papers from Nanjing University’s Large Model Center Accepted by CVPR 2025
CVPR (the IEEE/CVF Conference on Computer Vision and Pattern Recognition) is one of the world’s most influential annual academic conferences, covering cutting-edge research in computer vision, pattern recognition, and related fields. Each year it gathers top researchers, scholars, and industry professionals to discuss the latest technological advances and innovative applications. Topics range from image processing and machine learning to 3-D reconstruction and video analysis. All submissions undergo a rigorous peer-review process to ensure originality and academic value. In the 2024 Google Scholar Metrics, CVPR ranked second among all journals and conferences worldwide, just behind Nature.
The Large Model Center of the School of Computer Science at Nanjing University has had 12 papers accepted by CVPR 2025.
01
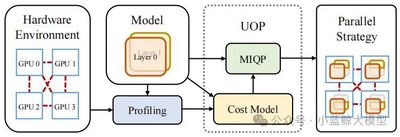
Title: UniAP: Unifying Inter- and Intra-Layer Automatic Parallelism by Mixed Integer Quadratic Programming
Authors: Hao Lin, Ke Wu, Jie Li, Jun Li, Wu-Jun Li
Affiliation: Nanjing University
Link: https://arxiv.org/abs/2307.16375
Abstract: Training large models usually demands multi-node, multi-GPU distributed setups. Even with ample hardware, 64 %–87 % of users (in our experiments) fail to obtain results because of sub-optimal hyper-parameters such as how the model and data are partitioned. Moreover, slow training is often tackled by adding GPUs while ignoring the decisive role of distributed algorithms in hardware utilization. Efficient algorithms deliver several-fold speed-ups—and cost cuts—over less efficient ones. Many existing strategies are inefficient and can even slow training as GPU count rises. We present UniAP, the first method to jointly optimize intra-layer (e.g., tensor parallelism) and inter-layer (e.g., pipeline parallelism) strategies via automatic search, together with a supporting platform. Given a model and hardware profile, UniAP automatically finds a high-performance scheme, achieving up to 3.8 × speed-up over the best prior work and up to 9 × over unoptimized baselines, while preventing the hyper-parameter mistakes that often cripple runs. UniAP has also been adapted to domestic AI accelerators. The paper was accepted as an Oral (0.7 % of submissions, 3.3 % of accepted papers) at CVPR 2025.
02
Title: Balanced Direction from Multifarious Choices: Arithmetic Meta-Learning for Domain Generalization
Authors: Xiran Wang, Jian Zhang, Lei Qi, Yinghuan Shi
Affiliation: Nanjing University; Southeast University
Link: https://arxiv.org/abs/2503.18987
Abstract: Domain generalization tackles distribution shifts between source (training) and unseen target (test) domains. First-order meta-learning based on gradient alignment finds balanced parameters across multiple sources, mitigating over-fitting. We reveal that gradient-aligned paths are not unique and that existing methods explore only one. Furthermore, they focus on directional alignment but ignore where in parameter space the model converges; ideally, the solution should lie near the centroid of each source optimum. We propose Arithmetic Meta-Learning (Arith), which introduces parameter averaging into meta-learning and designs an arithmetic-gradient optimizer that approximates the centroid while preserving gradient direction. Arith needs no extra expert networks or explicit regularizers and achieves strong generalization across benchmarks.

03
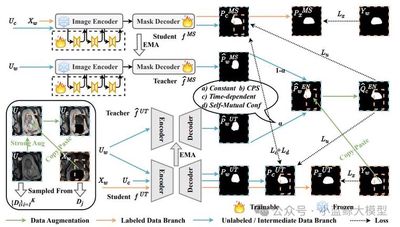
Title: Steady Progress Beats Stagnation: Mutual Aid of Foundation and Conventional Models in Mixed-Domain Semi-Supervised Medical Image Segmentation
Authors: Qinghe Ma, Jian Zhang, Zekun Li, Qian Yu, Lei Qi, Yinghuan Shi
Affiliation: Nanjing University; Southeast University
Link: https://arxiv.org/abs/2503.16997
Abstract: Large-scale pretrained vision foundation models show impressive generality, yet their rich priors can be a double-edged sword when adapted to specialized tasks. In medical-image segmentation with domain mismatch, foundation models such as MedSAM often yield over-confident but erroneous predictions, hampering leverage of unlabeled data. We introduce SynFoC, a framework that co-trains a foundation model with a from-scratch conventional model. The latter corrects high-confidence errors of the former, while the former supplies high-quality pseudo-labels early on. A Self-Mutual Confidence (SMC) module assesses pseudo-label quality and adaptively fuses them; a consensus–disagreement consistency constraint further boosts collaboration. Experiments confirm superior performance over existing approaches.
04
Title: Taste More, Taste Better: Diverse Data and Strong Model Boost Semi-Supervised Crowd Counting
Authors: Maochen Yang, Zekun Li, Jian Zhang, Lei Qi, Yinghuan Shi
Affiliation: Nanjing University; Southeast University
Link: https://arxiv.org/abs/2503.17984
Abstract: Crowd counting is vital in smart-city and public-safety applications, yet dense annotation is costly. Semi-supervised counting aims to exploit unlabeled data, but effective use remains challenging. We propose TMTB (Taste More Taste Better), advancing both data and model aspects. (1) Inpainting Augmentation uses diffusion models to regenerate image backgrounds without disturbing crowd structures, greatly enriching data diversity; unreliable regions are filtered. (2) Visual State Space Model (VSSM) serves as the backbone, capturing global context with linear complexity—ideal for extreme density, low light, or bad weather. (3) A noise-robust classification head supplies coarse-but-stable interval-count supervision, mitigating regression sensitivity to label noise. On multiple datasets, TMTB outperforms state-of-the-art methods under 5 %, 10 %, and 40 % label fractions; on JHU-Crowd++ with only 5 % labels it lowers MAE below 70 for the first time (67.0) and shows strong cross-domain generalization.

05
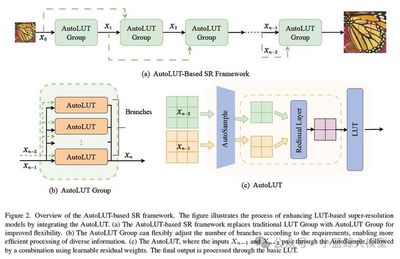
Title: AutoLUT: LUT-Based Image Super-Resolution with Automatic Sampling and Adaptive Residual Learning
Authors: Yuheng Xu, Shijie Yang, Xin Liu, Jie Liu, Jie Tang, Gangshan Wu
Affiliation: Nanjing University
Link: https://arxiv.org/abs/2503.01565
Abstract: The spread of high-DPI displays heightens demand for high-def images, yet edge devices struggle to host heavy SR networks, calling for efficiency. Prior LUT-based SR has scarcely mined pixel-level cues and uses fixed sampling, limiting accuracy and fine-detail capture. We introduce two plug-and-play modules: AutoSample, which learns flexible LUT sampling weights during training—adapting to pixel variations, enlarging receptive field, and incurring no inference overhead—and AdaRL, which strengthens inter-layer connections to boost fine-detail reconstruction. With similar storage, AutoLUT lifts MuLUT by ≈ 0.20 dB PSNR across five datasets; on SPF-LUT it halves storage, cuts inference time by two-thirds, and maintains fidelity.
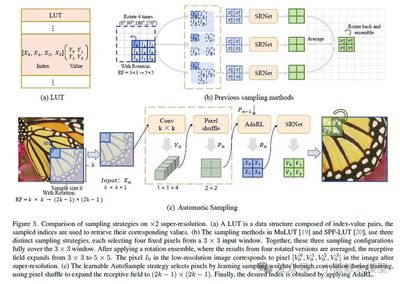
06
Title: CATANet: Efficient Content-Aware Token Aggregation for Lightweight Image Super-Resolution
Authors: Xin Liu, Jie Liu, Jie Tang, Gangshan Wu
Affiliation: Nanjing University
Link: https://arxiv.org/abs/2503.06896
Abstract: Transformer-based SR excels on low-level vision but its quadratic complexity explodes with resolution. Existing speed-ups partition images into content-agnostic windows, curtailing long-range redundancy exploitation vital for SR. We propose CATANet, a lightweight Content-Aware Token Aggregation Network. A novel aggregation module clusters content-similar tokens across the entire image, sharing aggregation centers and updating them only during training to cut computation. We then apply intra-group self-attention for long-range interaction and inter-group cross-attention to enhance global fusion. Compared with the clustering-based SPIN, CATANet is faster at inference while gaining up to 0.33 dB PSNR.
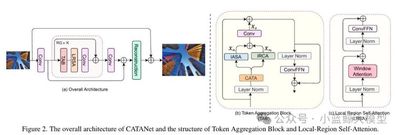
07
Title: Tra-MoE: Learning Trajectory Prediction Model from Multiple Domains for Adaptive Policy Conditioning
Authors: Jiange Yang, Haoyi Zhu, Yating Wang, Gangshan Wu, Tong He, Limin Wang
Affiliation: Nanjing University; Shanghai AI Lab; USTC; Tongji University
Link: https://arxiv.org/pdf/2411.14519
Abstract: Data scarcity and heterogeneity challenge robot learning. Tra-MoE adopts a sparsely gated Mixture-of-Experts to learn trajectory prediction from large-scale cross-domain video without action labels, balancing parameter sharing and specialization. It fuses simulation videos rendered by different physics engines with real videos of humans, single-arm, and dual-arm robots—promising for cross-agent learning. An adaptive policy-conditioning mechanism leverages predicted trajectories to boost downstream robot control, greatly reducing needs for expensive real-robot data.
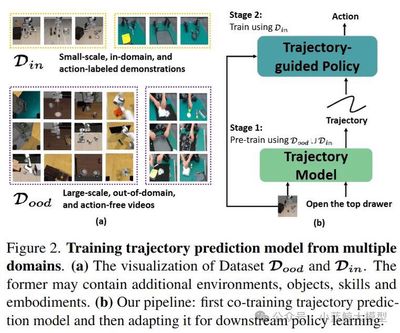
08
Title: LeviTor: 3-D Trajectory Oriented Image-to-Video Synthesis
Authors: Hanlin Wang, Hao Ouyang, Qiuyu Wang, Wen Wang, Ka Leong Cheng, Qifeng Chen, Yujun Shen, Limin Wang
Affiliation: Nanjing University; Ant Group; Zhejiang University; Hong Kong University of Science and Technology; Shanghai AI Lab
Link: https://github.com/ant-research/LeviTor
Abstract: Sketching a trajectory is an intuitive way to control motion in image-to-video synthesis, yet 2-D paths are ambiguous for out-of-plane motion. LeviTor enriches interaction by adding a depth dimension: users assign relative depth to trajectory key-points, retaining 2-D convenience while enabling 3-D control. Objects are represented by a few cluster points reflecting depth and occlusion. These, along with depth and instance maps, guide a video-diffusion generator to produce videos faithfully following 3-D trajectories. Extensive experiments demonstrate precise motion control and high realism.

09
Title: Contextual AD Narration with Interleaved Multimodal Sequence
Authors: Hanlin Wang, Zhan Tong, Kecheng Zheng, Yujun Shen, Limin Wang
Affiliation: Nanjing University; KU Leuven; Ant Group; Shanghai AI Lab
Link: https://arxiv.org/abs/2403.12922
Abstract: Audio description (AD) narrates visual content for the visually impaired. We present Uni-AD, a simple unified framework that feeds interleaved multimodal sequences—video features, text, character lists, and context—into a pretrained language model. A lightweight mapper aligns video to text space for fine-grained fusion; a character-optimization module highlights major roles in context. Coupled with context cues and a contrastive loss, Uni-AD generates fluent, context-aware narration. Experiments on multiple AD datasets confirm its superiority.
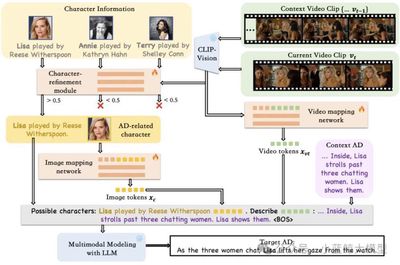
10
Title: Multiple Object Tracking as ID Prediction
Authors: Ruopeng Gao, Ji Qi, Limin Wang
Affiliation: Nanjing University; China Mobile (Jiangsu) Software Technology Co.; Shanghai AI Lab
Link: https://github.com/MCG-NJU/MOTIP
Abstract: Multi-object tracking (MOT) is traditionally decomposed into detection and association, with handcrafted algorithms maintaining trajectories and computing cost matrices—effective yet requiring extensive tuning for complex scenes. We reconceptualize MOT as context-conditioned ID prediction and propose MOTIP, an end-to-end framework that directly decodes ID labels for current detections given past trajectories. Using only appearance features, MOTIP achieves state-of-the-art results on multiple benchmarks without elaborate tricks, offering a powerful baseline for future research.
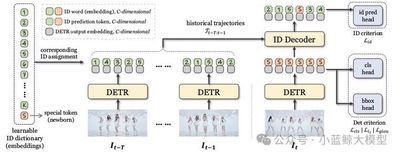
11
Title: Online Video Understanding: OVBench and VideoChat-Online
Authors: Zhenpeng Huang, Xinhao Li, Jiaqi Li, Jing Wang, Xiangyu Zeng, Cheng Liang, Tao Wu, Xi Chen, Liang Li, Limin Wang
Project Site: https://videochat-online.github.io/
Affiliation: Nanjing University; China Mobile Research Institute; Shanghai AI Lab
Abstract: Multimodal large language models have excelled at offline video understanding, but real-time scenarios (e.g., autonomous driving, HCI) pose fresh challenges. We contribute on three fronts: (1) OVBench, a comprehensive QA benchmark evaluating perception, memory, and reasoning over streaming video, spanning six task types across past, current, and future contexts (16 subtasks from diverse datasets). (2) Pyramid Memory Bank, which efficiently retains critical spatio-temporal cues. (3) An offline-to-online learning paradigm, with an alternating dialog format and the VideoChatOnline-IT instruction-tuning set for streaming data. Our resulting framework, VideoChat-Online, outperforms state-of-the-art offline and online models on common offline benchmarks and OVBench, despite lower compute cost.
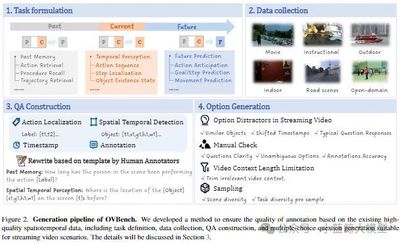
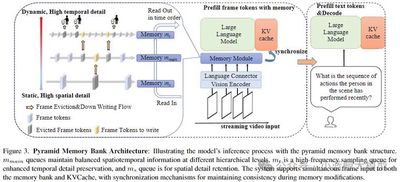
12
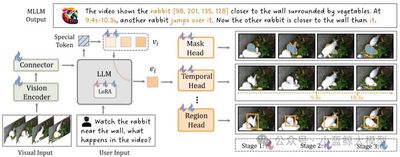
Title: Task Preference Optimization: Improving Multimodal Large Language Models with Vision Task Alignment
Authors: Zi’ang Yan, Zhilin Li, Yinan He, Chenting Wang, Kunchang Li, Xinhao Li, Xiangyu Zeng, Zilei Wang, Yali Wang, Yu Qiao, Limin Wang, Yi Wang
Affiliation: Shanghai AI Lab; Zhejiang University; University of Science and Technology of China; Shanghai Jiao Tong University; Shenzhen Institutes of Advanced Technology, CAS; Nanjing University
Abstract: Although multimodal LLMs excel at broad visual reasoning, they lag on fine-grained or high-precision tasks. Prior efforts either add tool-usage skills or fold specific vision tasks into the autoregressive framework, often harming overall multimodal performance. We propose Task Preference Optimization (TPO), which introduces differentiable task preferences distilled from fine-grained vision tasks to guide optimization. Learnable task tokens form dynamic links between multiple task-specific heads and the core MLLM, enabling effective use of rich labeled data. TPO supports joint multi-task training, boosting overall performance by 14.6 % versus baselines and delivering strong zero-shot generalization comparable to fully-supervised state-of-the-art models. We instantiate TPO on VideoChat and LLaVA, confirming significant gains and opening a scalable pathway to enhance MLLMs on diverse visual tasks.